Wprowadzenie.
W poprzednim wpisie dotyczącym protokołu Modbus TCP (Modbus TCP cz I) przedstawiłem jak wygląda ramka protokołu, jaką strukturę ma nagłówek MBAP oraz wymieniłem i opisałem kategorie kodów funkcyjnych.
Przed przystąpieniem do praktycznej implementacji protokołu na Raspberry Pi przedstawię jeszcze jak wygląda stos komunikacji Modbus TCP, jak wyglądają typy danych w Modbus’ie, w jaki sposób można zorganizować pamięć danych w urządzeniu oraz przedstawię publiczne kody funkcyjne.
Zakres artykułu.
- Stos komunikacyjny w modu sieciowym OSI i TCP/IP a protokoł Modbus TCP
- Typy danych w protokole Modbus
- Przykłady organizacji pamięci danych
- Publiczne kody funkcyjne
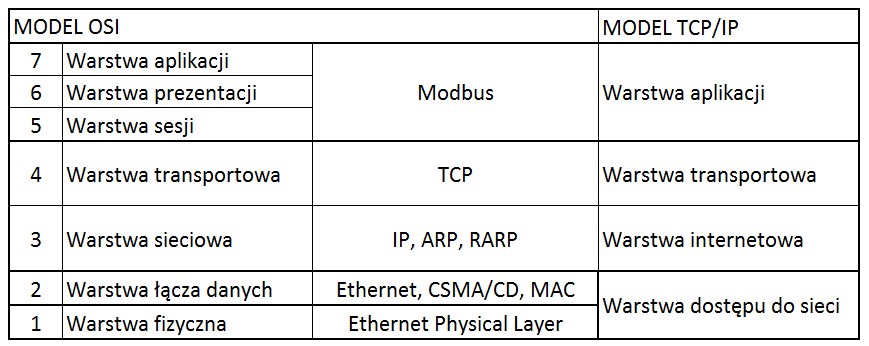
Stos komunikacyjny w modu sieciowym OSI i TCP/IP a protokoł Modbus TCP
Zajmując się protokołem Modbus warto wiedzieć, że ramka protokołu Modbus ADU (application data unit) znajduje się w warstwie aplikacji modelu sieciowego TCP/IP. Takie usytuowanie ramki oznacza, że gdy wysyłamy dane przy pomocy protokołu Modbus TCP dane przechodzą przez każdą następną warstwę modu sieciowego i są zaopatrywane w kolejne nagłówki protokołów tych warstw. Proces ten nazywamy hermetyzacją danych (ang. encapsulated). Gdy ramka dojdzie do najniższej warstwy modelu sieciowego (warstwy fizycznej) dane zamieniane są na sygnały elektryczne i przesyłane do punktu docelowego. W urządzeniu docelowym odbywa się odwrotny proces, to znaczy dane są odpakowywane aż w warstwie aplikacji zostanie jedynie ramka protokołu Modbus – ADU.
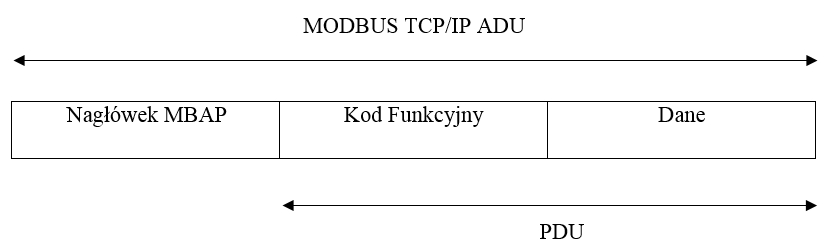
Ramka protokołu Modbus TCP.
Typy danych w protokole Modbus
Typy danych w protokole Modbus możemy podzielić na pojedyncze bity oraz rejestry które składają się z 16 bitów. Kolejny podział polega na tym, że niektóre dane są danymi wejściowymi co oznacza, że stan ich możemy jedynie odczytać oraz występują dane wyjściowe, których stan możemy nie tylko odczytać ale również wymusić/ustawić. Poniższa tabela przedstawia typy dane wykorzystywane w protokole Modbus.

Przykłady organizacji pamięci danych
W urządzeniach, które wykorzystują protokół Modbus przeważnie możemy się spotkać z dwoma sposobami najczęściej stosowanymi organizacjami pamięci danych. Jednakże należy pamiętać, że nie są jedyne możliwe do implementacji rozwiązania.
Pierwszy model bazuje na utworzeniu odseperowanych bloków pamięci. To rozwiązanie charakteryzuje się tym, że poprzez określone kody funkcyjne mamy dostęp jedynie do określonych komórek pamięci. W takiej organizacji pamięci pomiędzy blokami nie występują współzależności. Poniżej przedstawiłem graficznie jak wygląda taka struktura pamięci danych.
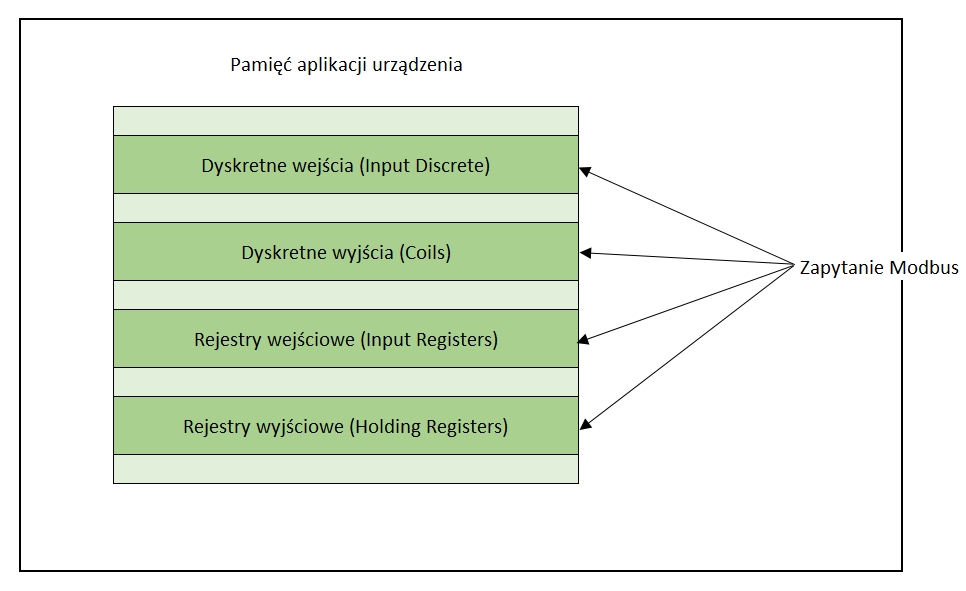
Drugi model organizacji pamięci składa się z jednego wspólnego bloku pamięci. Rozwiązanie to w odróżnieniu od poprzedniego pozwala na dostęp do tych samych danych poprzez różne kody funkcyjne. W takiej organizacji pamięci pomiędzy blokami mogą występować współzależności między danymi. Podobnie jak w poprzednim przypadku przedstawiłem graficznie jak wygląda taka struktura pamięci danych.
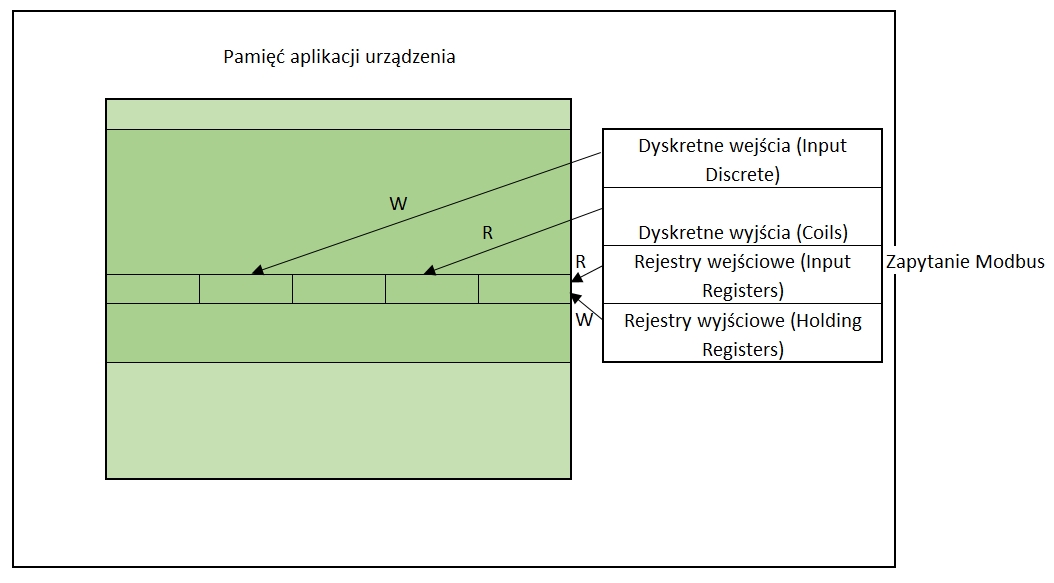
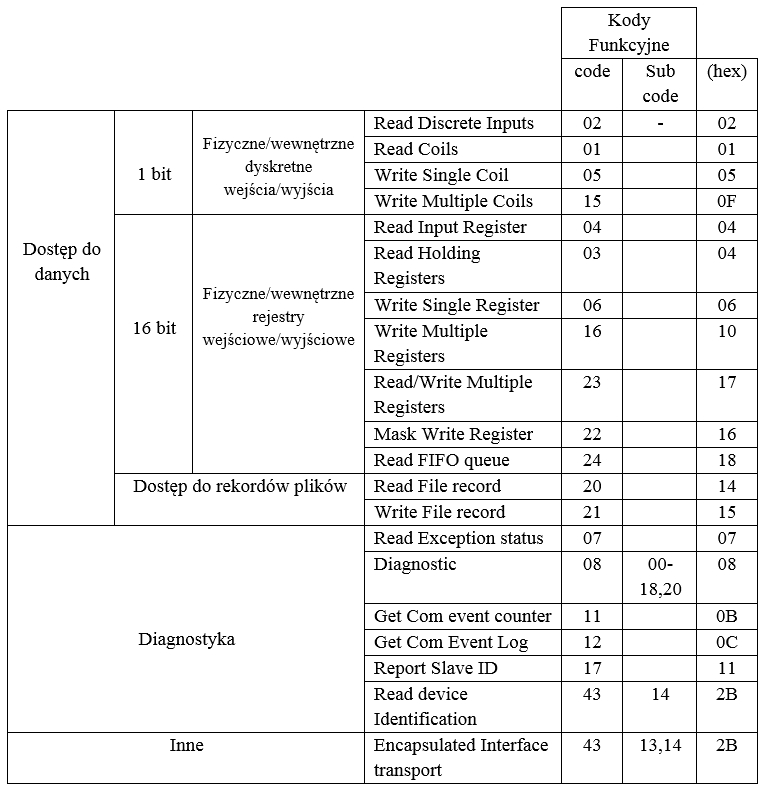
Publiczne kody funkcyjne
W poprzedniej części wpisu wspomniałem, że występują trzy kategorie kodów funkcyjnych. Jedną z tych grup były kody publiczne, których są określone w standardzie Modbus. Poniżej zamieściłem tabelę z publicznymi kodami funkcyjnymi, które opisane są w dokumencie MODBUS APPLICATION PROTOCOL SPECIFICATION v1.1b