
Wprowadzenie.
We wpisie przedstawiłem, w jaki sposób pobierać (zeskrobywać) dane ze strony internetowej. W tym celu zastosowałem moduł requests oraz BeautifulSoup.
Zakres artykułu.
- Pobieranie (zeskrobywanie) danych ze stron www
Pobieranie (zeskrobywanie) danych ze stron www
Zanim zaczniemy pisać program, znajdźmy jakąś stronę, na której będą znajdowały się jakieś ciekawe dane. Na potrzeby tego wpisu skorzystałem ze strony https://www.biznesradar.pl/, na której możemy między innymi znaleźć historyczne wartości cen akcji spółek. Przejdźmy teraz na tej stronie do jednej z wybranej przez nas spółki, a następnie sprawdźmy jej historyczne notowania. Ja wybrałem dla przykładu akcje spółki CD Projekt, a jej historyczne notowania znajdują się pod tym linkiem. Na stronie widzimy tabelę, w której znajdują się różne dane.
Przejdźmy teraz do naszego środowiska programistycznego i zaimportujmy dwa moduły. Jeden moduł to requests a drugi BeautifulSoup. Jeżeli nie posiadamy jeszcze tych modułów, to możemy je pobrać przy pomocy narzędzia pip następującymi poleceniami.
pip3 install requests
pip3 install beautifulsoup4
Moduły możemy zaimportować w następujący sposób.
import requests from bs4 import BeautifulSoup
W kolejnym kroku będziemy potrzebowali adresu strony, na której znajduje się tabela z danymi. Adres ten przypiszemy do naszej zmiennej w postaci stringu.
my_url = "https://www.biznesradar.pl/notowania-historyczne/CD-PROJEKT"
Następnie z wykorzystanie modułu requests przy pomocy metody get(), pobieramy kod html całej strony.
my_html = requests.get(my_url)
Gdy na tym etapie, będziemy chcieli sprawdzić, czy kod się pobrał poprawnie, wówczas możemy go wyświetlić w konsoli przy pomocy printa, gdzie w moim przypadku jako argument należy podać my_html.text.
print(my_html.text)
Cały kod na chwilę obecną wygląda następująco.
import requests from bs4 import BeautifulSoup my_url = "https://www.biznesradar.pl/notowania-historyczne/CD-PROJEKT" my_html = requests.get(my_url) print(my_html.text)
Po wykonaniu tego kodu w terminalu powinniśmy zobaczyć kod pobranej przez nas strony. Ze względu, że kod ten jest bardzo obszerny, nie będę go tu zamieszczać.
W następnym kroku, przy pomocy modułu BeautifulSoup będziemy przetwarzać pobrany kod strony internetowej. Dokumentację BeautifulSoup możemy znaleźć pod tym linkiem. W tym momencie pobrany przez nas kod musimy zwrócić jako obiekt BeautifulSoup, dzięki czemu otrzymamy zagnieżdżoną strukturę danych.
my_soup = BeautifulSoup(my_html.text, 'html.parser')
Następnie przejdźmy z powrotem na stronę, gdzie jest tabela z danymi i odnajdźmy kod odpowiedzialny za stworzenie tej tabeli. W przeglądarce Chrome możemy szybko odnaleźć interesujący nasz kod poprzez naciśnięcie na szukany element prawym przyciskiem myszy i wybranie opcji Zbadaj. Dzięki tej czynności powinien pojawić nam się kod z zaznaczonym fragmentem kodu elementu, na który nacisnęliśmy ppm.
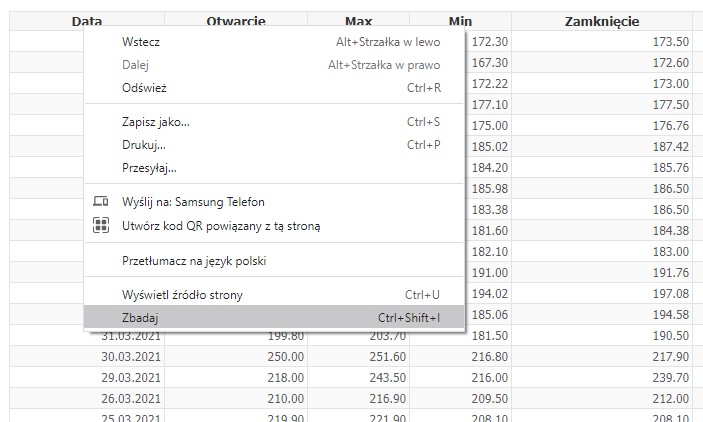
W moim przypadku kod prezentuje się następująco.
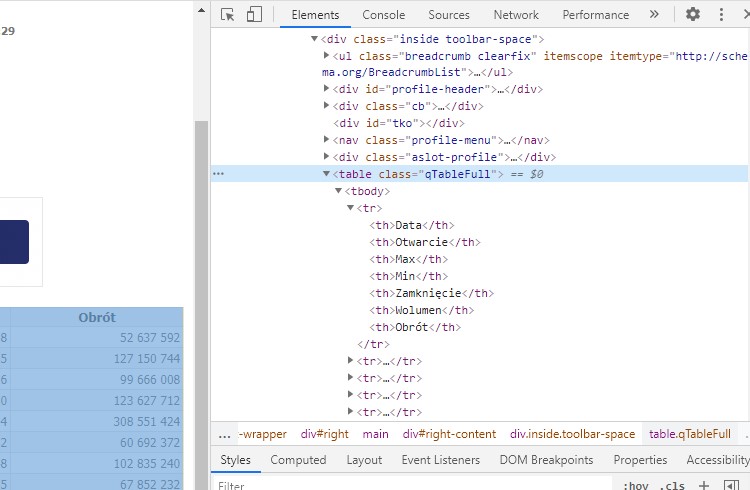
W kodzie możemy zobaczyć, że tabela posiada atrybut class. Do atrybutu class przypisana jest wartość qTableFull i to do tej wartości będziemy się odwoływać w naszym programie. Jeżeli chcemy znaleźć dokładną wartość stringu określonego atrybutu w określonym elemencie, wówczas należy zastosować metodę find_all.
Kod w naszym przypadku wygląda następująco.
my_table = my_soup.find_all("table", class_="qTableFull")[0]
Ze względu na to, że metoda find_all zwraca wszystkie elementy, które będą pasować do naszego klucza wyszukiwań, dlatego musimy odnieść się do konkretnego elementu. Ponieważ kod naszej strony internetowej zawiera tylko jedną tabelę z atrybutem class=”qTableFull”, dlatego odwołujemy się do pierwszego, to jest do zerowego elementu. W tym momencie możemy podejrzeć, co znajduje się w obiekcie my_table przy pomocy printa.
print(my_table)
W tym miejscu warto wspomnieć, że moduł BeautifulSoup dostarcza nam metodę prettify(), która formatuje tekst, dzięki czemu mamy poprawioną czytelność wyświetlonych informacji w terminalu.
print(my_table.prettify())
Cały kod do chwili obecnej prezentuje się w następujący sposób.
import requests
from bs4 import BeautifulSoup
my_url = "https://www.biznesradar.pl/notowania-historyczne/CD-PROJEKT"
my_html = requests.get(my_url)
my_soup = BeautifulSoup(my_html.text, 'html.parser')
my_table = my_soup.find_all("table", class_="qTableFull")[0]
print(my_table.prettify())