
Wprowadzenie.
W części drugiej wpisu o pobieraniu danych ze stron www przedstawiłem, w jaki sposób otrzymać konkretne dane bez “ozdobników”, które mogą być już bezpośrednio użyte przy dowolnych działaniach.
Zakres artykułu.
- Pobieranie (zeskrobywanie) danych ze stron www
Pobieranie (zeskrobywanie) danych ze stron www
Na chwilę obecną dane, które wyświetliliśmy w poprzedniej części, nie są gotowe do ich przetwarzania, ponieważ jak możemy zobaczyć, wartości opatrzone są tagami html. W związku z tym musimy tak napisać program, aby pozbyć się zbędnych elementów w kodzie.
Przyjrzyjmy się, jak aktualnie wygląda nasza odpowiedź w terminalu.
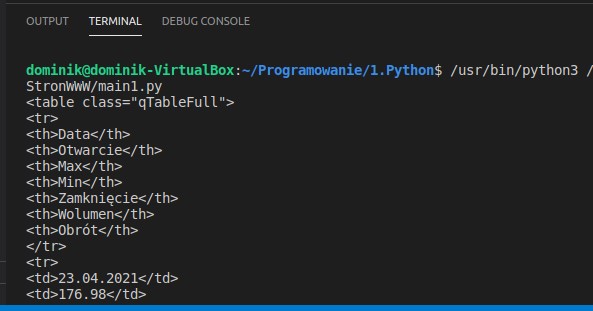
Jak możemy zobaczyć, poza tagiem table znajdują się takie tagi jak: tr, th, oraz td. Tag tr definiuje jeden rząd w tabeli. Tag th definiuje wartość pola, która nazywa poszczególne kolumny. Natomiast tag td również definiuje wartości pola, z tym że tag ten obejmuje konkretne dane.
Moduł BeautifulSoup dostarcza nam taką metodę jak select(), która znajduje określone przez nas tagi. W wyniku, który wcześniej otrzymaliśmy, zastosujemy teraz metodę select(), gdzie będziemy chcieli znaleźć jedynie tagi th. Kod reazlizujący to zadanie wygląda następująco.
my_data1 = my_table.select('th')
Wyświetlmy teraz, co zawiera obiekt my_data1 przy pomocy następującego kodu.
print(my_data1)
Wynik, jaki powinniśmy otrzymać, wygląda następująco.
[<th>Data</th>, <th>Otwarcie</th>, <th>Max</th>, <th>Min</th>, <th>Zamknięcie</th>, <th>Wolumen</th>, <th>Obrót</th>]
Dane umieszczone są w liście, a co za tym idzie, możemy je iterować.
for el in my_data1:
print(el.text)
Uzyskany wynik prezentuje się teraz następująco.
Data
Otwarcie
Max
Min
Zamknięcie
Wolumen
Obrót
Intuicyjnie spodziewalibyśmy się otrzymać dane w tagach, jednakże metoda select() nie zwraca listy, a obiekt, w którym przy iterowaniu kolejnych elementów, tagi htmla są usuwane.
Identycznie postępujemy z danymi opatrzonymi tagiem td.
my_data2 = my_table.select('td')
for el in my_data2:
print(el.text)
Niewielki fragment wyniku, jaki powinniśmy otrzymać, wygląda następująco.
23.04.2021
176.98
179.00
167.50
171.14
708 623
121 039 464
22.04.2021
175.70
176.70
172.30
…
W tym momencie mamy dostępne wszystkie dane jako kolejne elementy co niekoniecznie jest naszym ostatecznym celem. Z danych, które posiadamy, wyodrębnijmy datę oraz kurs na zamknięciu. W celu zrealizowania tego zadania musimy wykonać kilka dodatkowych kroków.
W pierwszej kolejności, gdy iterujemy obiekt my_data1, zliczmy liczbę kolumn.
number_of_columns = 0
for el in my_data1:
number_of_columns += 1
print(number_of_columns)
Otrzymany wynik powinien wyglądać następująco.
7
W następnym kroku zmodyfikujmy pętlę, która iteruje po zmiennej my_data2, tak aby data oraz kurs na zamknięciu były umieszczane w naszych listach.
i = 0
for el in my_data2:
i += 1
if i == 1:
my_date.append(el.text)
if i == 5:
my_closing_price.append(el.text)
if i == number_of_columns:
i = 0
print(my_date)
print(my_closing_price)
Otrzymany wynik wygląda następująco.
[‘23.04.2021’, ‘22.04.2021’, ‘21.04.2021’, ‘20.04.2021’, ‘19.04.2021’, ‘16.04.2021’, ‘15.04.2021’, ‘14.04.2021’, ‘13.04.2021’, ‘12.04.2021’, ‘09.04.2021’, ‘08.04.2021’, ‘07.04.2021’, ‘06.04.2021’, ‘01.04.2021’, ‘31.03.2021’, ‘30.03.2021’, ‘29.03.2021’, ‘26.03.2021’, ‘25.03.2021’, ‘24.03.2021’, ‘23.03.2021’, ‘22.03.2021’, ‘19.03.2021’, ‘18.03.2021’, ‘17.03.2021’, ‘16.03.2021’, ‘15.03.2021’, ‘12.03.2021’, ‘11.03.2021’, ‘10.03.2021’, ‘09.03.2021’, ‘08.03.2021’, ‘05.03.2021’, ‘04.03.2021’, ‘03.03.2021’, ‘02.03.2021’, ‘01.03.2021’, ‘26.02.2021’, ‘25.02.2021’, ‘24.02.2021’, ‘23.02.2021’, ‘22.02.2021’, ‘19.02.2021’, ‘18.02.2021’, ‘17.02.2021’, ‘16.02.2021’, ‘15.02.2021’, ‘12.02.2021’, ‘11.02.2021’]
[‘171.14’, ‘173.50’, ‘172.60’, ‘173.00’, ‘177.50’, ‘176.76’, ‘187.42’, ‘185.76’, ‘186.50’, ‘186.50’, ‘184.38’, ‘183.00’, ‘191.76’, ‘197.08’, ‘194.58’, ‘190.50’, ‘217.90’, ‘239.70’, ‘212.00’, ‘208.10’, ‘217.10’, ‘220.70’, ‘217.00’, ‘223.20’, ‘220.70’, ‘231.00’, ‘229.50’, ‘229.90’, ‘226.50’, ‘221.00’, ‘210.20’, ‘223.00’, ‘232.00’, ‘232.00’, ‘235.00’, ‘228.30’, ‘241.30’, ‘240.30’, ‘236.60’, ‘251.60’, ‘258.20’, ‘257.70’, ‘258.10’, ‘265.40’, ‘275.00’, ‘271.30’, ‘270.10’, ‘270.00’, ‘263.00’, ‘270.50’]
Tak przygotowane dane możemy teraz swobodnie wykorzystywać do różnych celów, jak na przykład wyświetlenie wartości na wykresie, o czym napiszę w następnym wpisie tej serii.
Na koniec zamieszczam jeszcze cały kod programu.
import requests
from bs4 import BeautifulSoup
my_url = "https://www.biznesradar.pl/notowania-historyczne/CD-PROJEKT"
my_html = requests.get(my_url)
my_soup = BeautifulSoup(my_html.text, 'html.parser')
my_table = my_soup.find_all("table", class_="qTableFull")[0]
my_data1 = my_table.select('th')
my_data2 = my_table.select('td')
number_of_columns = 0
for el in my_data1:
number_of_columns += 1
my_date = []
my_closing_price = []
i = 0
for el in my_data2:
i += 1
if i == 1:
my_date.append(el.text)
if i == 5:
my_closing_price.append(el.text)
if i == number_of_columns:
i = 0
print(my_date)
print(my_closing_price)